2 min
Introduction To SVM in 2 minutes
Support Vector Machine (SVM) is a powerful supervised machine learning algorithm used for classification and regression tasks. Its primary objective is to find the optimal hyperplane that separates the data into different classes. Here’s a detailed overview of SVM
Support Vector Machine (SVM) is a powerful supervised machine learning algorithm used for classification and regression tasks. Its primary objective is to find the optimal hyperplane that separates the data into different classes. Here’s a detailed overview of SVM:
Key Concepts
- Hyperplane: In an n-dimensional space, a hyperplane is an (n-1)-dimensional subspace that divides the space into two distinct parts. For a 2D space, this is a line; for a 3D space, it's a plane.
- Support Vectors: These are the data points that are closest to the hyperplane. They are critical in defining the position and orientation of the hyperplane. The SVM algorithm uses these points to maximize the margin between the classes.
- Margin: The margin is the distance between the hyperplane and the nearest data point from either class. SVM aims to maximize this margin to improve the classifier’s robustness and generalizability.
Working of SVM
- Linear SVM: For linearly separable data, SVM finds a straight hyperplane that separates the classes. The algorithm identifies the support vectors and maximizes the margin between the support vectors and the hyperplane.
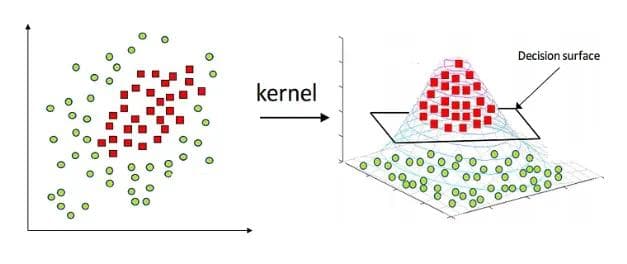
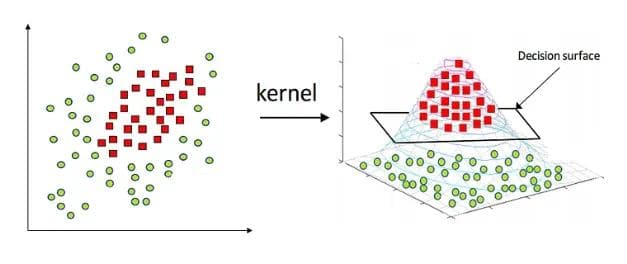
- Non-linear SVM: When the data is not linearly separable, SVM uses a technique called the kernel trick. Kernels transform the data into a higher-dimensional space where a linear separator can be found. Common kernels include: